为什么要使用条件变量?
前言
最近看了很多与线程有关的 C++ 新特性,条件变量是见的比较多的一个特性。
看的时候我发现,想要理解一个新的特性,关键的要看它的引入到底解决了哪些问题,没有什么特性我们要实现相同的功能要怎么做?
以我的理解来看,条件变量是一个线程间互相同步与通知的手段,他通过主动唤醒的方式减小了各个线程的开销,取代了简单但是消耗较大的一直被动循环检验与等待。
没有条件变量我们如何实现相同的需求?
这里采用现代C++教程1 中关于条件变量的一个例子作为基础:
不使用条件变量版本
#include <queue>
#include <chrono>
#include <mutex>
#include <thread>
#include <iostream>
#include <condition_variable>
int main() {
std::queue<int> produced_nums;
std::mutex mtx;
// 生产者
auto producer = [&]() {
for (int i = 0; ; i++) {
std::this_thread::sleep_for(std::chrono::milliseconds(900));
std::unique_lock<std::mutex> lock(mtx);
std::cout << "producing " << i << std::endl;
produced_nums.push(i);
}
};
// 消费者
auto consumer = [&]() {
while (true) {
{
std::unique_lock<std::mutex> lock(mtx);
if(produced_nums.empty()) continue;
}
std::unique_lock<std::mutex> lock(mtx);
// 短暂取消锁,使得生产者有机会在消费者消费空前继续生产
lock.unlock();
// 消费者慢于生产者
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
lock.lock();
while (!produced_nums.empty()) {
std::cout << "consuming " << produced_nums.front() << std::endl;
produced_nums.pop();
}
}
};
// 分别在不同的线程中运行
std::thread p(producer);
std::thread cs[2];
for (int i = 0; i < 2; ++i) {
cs[i] = std::thread(consumer);
}
p.join();
for (int i = 0; i < 2; ++i) {
cs[i].join();
}
return 0;
}
使用条件变量版本
#include <queue>
#include <chrono>
#include <mutex>
#include <thread>
#include <iostream>
#include <condition_variable>
int main() {
std::queue<int> produced_nums;
std::mutex mtx;
std::condition_variable cv;
bool notified = false; // 通知信号
// 生产者
auto producer = [&]() {
for (int i = 0; ; i++) {
std::this_thread::sleep_for(std::chrono::milliseconds(900));
std::unique_lock<std::mutex> lock(mtx);
std::cout << "producing " << i << std::endl;
produced_nums.push(i);
notified = true;
cv.notify_all(); // 此处也可以使用 notify_one
}
};
// 消费者
auto consumer = [&]() {
while (true) {
std::unique_lock<std::mutex> lock(mtx);
while (!notified) { // 避免虚假唤醒
cv.wait(lock);
}
// 短暂取消锁,使得生产者有机会在消费者消费空前继续生产
lock.unlock();
// 消费者慢于生产者
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
lock.lock();
while (!produced_nums.empty()) {
std::cout << "consuming " << produced_nums.front() << std::endl;
produced_nums.pop();
}
notified = false;
}
};
// 分别在不同的线程中运行
std::thread p(producer);
std::thread cs[2];
for (int i = 0; i < 2; ++i) {
cs[i] = std::thread(consumer);
}
p.join();
for (int i = 0; i < 2; ++i) {
cs[i].join();
}
return 0;
}
这两段代码在效果上是等效的,都是一个生产者两个消费者。
前者使用了 while 循环来一直检查是否可以消费,后者使用了 cv.wait(lock) 条件变量来实现阻塞等待可消费的提醒。
可以发现在这个例子里,前者是主动的去检查是否可以消费,后者是被动的被提醒可以消费,而主动则代表着需要一直询问查询,主动的 while 循环检查始终在重复如下流程:
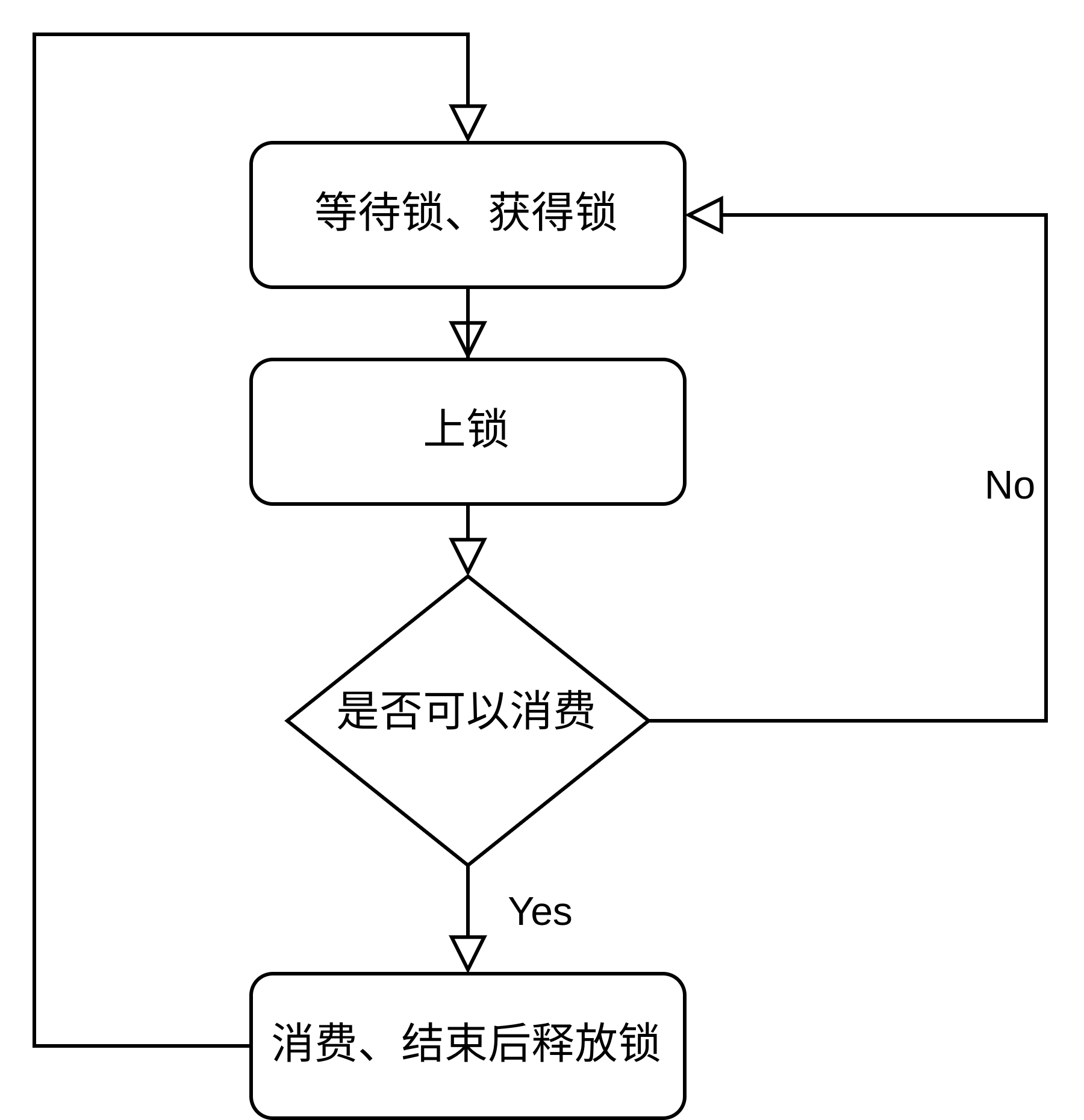
而这个上锁、检查、释放锁的过程就是非常冗余、消耗资源、效率低下的,而条件变量解决了这个问题,条件变量做的事:
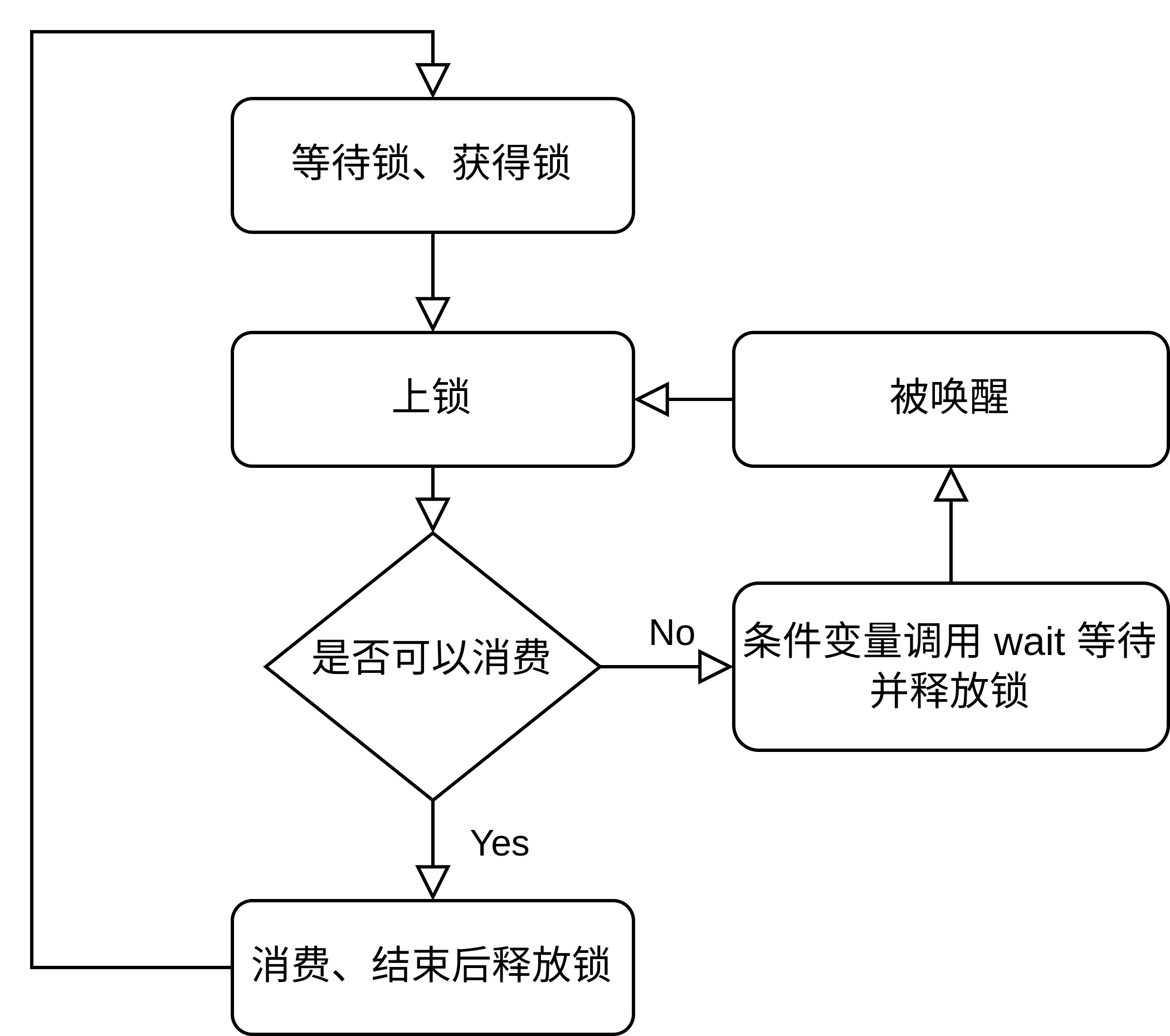
这里需要注意的一点是,在条件变量调用 wait() 时,做了两件事,一个是阻塞线程等待其他线程唤醒、另一个是释放锁,只有这样才会让别的线程有机会获得锁,而被唤醒后又会自动上锁。
为什么要和 mutex 与 lock 一起用?
我们常见的搭配就是 condition_variable、mutex、unique_lock 一起使用,那么为什么要这么做呢?
一个比较常见的说法是,在调用 wait() 函数与线程真正的阻塞等待状态是存在一定时间差的,那么就会存在唤醒丢失的问题,一种情况如下:
线程A: ------- 调用 wait() 函数 ------- 进入等待状态 ------
线程B: -------------------------唤醒A-------------------
而我们希望的是:
线程A: ------- 调用 wait() 函数 ------- 进入等待状态 ------
线程B: -------------------------------------------唤醒A-
我们总是要确保,在线程 A 真正进入等待状态后再进行唤醒,因此这里需要一个 lock 来保证我们对于一个线程空闲/等待的改变是原子性的,也就是不应该被其他线程中途干扰。
为什么使用 unique_lock 而不使用 scoped_lock 或 lock_guard
首先三个函数都是 RAII 的锁管理函数,可以有效解决 lock 后忘记 unlock 的情形,而目前在 C++17 后推荐统一使用 scoped_lock 而不是 lock_guard。
而使用 unique_lock 是因为我们在使用条件变量时,需要在条件变量 wait 时解除 lock,只有 unique_lock 能够满足这个条件,实现自己更细粒度的锁区间的划分。
什么是虚假唤醒?
可以注意到在第一部分代码中有这么一段:
auto consumer = [&]() {
while (true) {
std::unique_lock<std::mutex> lock(mtx);
while (!notified) { // 避免虚假唤醒
cv.wait(lock);
}
// ...
notified = false;
}
};
避免虚假唤醒,那么什么是虚假唤醒呢?
虚假唤醒简而言之就是,没有满足消费的条件却被唤醒后进行了消费。
这个发生的可能多是在系统调度层面,具体的可以参考此知乎问题:为什么条件锁会产生虚假唤醒现象(spurious wakeup)?
而解决的方案就是在消费之前再检查一下是否满足消费的条件,而这个消费条件多是用一个形如 notified 的 bool 变量来标识是否可以消费。
如果不检查,带条件变量的执行流程就会像如下这样:
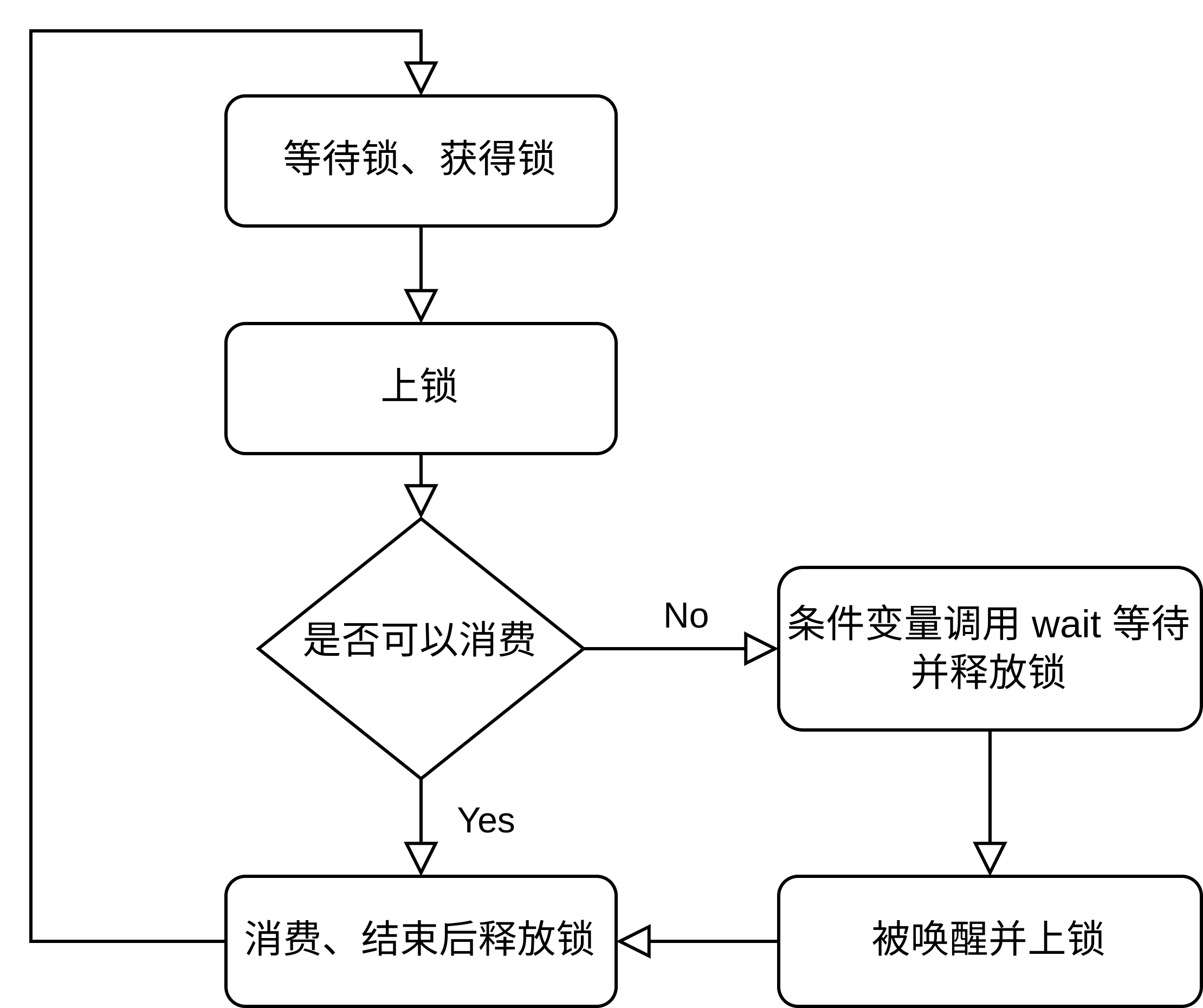
其中少了一步检查是否可以消费的过程。
后记
本文记录了我在学习条件变量过程中的一些疑问,如有错误之处,敬请交流指正。