前言
前一阵学校有五一数模节校赛,和朋友一起参加做B题,波士顿房价预测,算是第一次自己动手实现一个简单的小网络吧,虽然很简单,但还是想记录一下。
题目介绍
波士顿住房数据由哈里森和鲁宾菲尔德于1978年Harrison and Rubinfeld1收集。它包括了波士顿大区每个调查行政区的506个观察值。1980年Belsley et al.2曾对此数据做过分析。
数据一共14列,每一列的含义分别如下:
| 英文简称 | 详细含义 |
|---|---|
| CRIM | 城镇的人均犯罪率 |
| ZN | 大于25,000平方英尺的地块的住宅用地比例。 |
| INDUS | 每个镇的非零售业务英亩的比例。 |
| CHAS | 查尔斯河虚拟变量(如果环河,则等于1;否则等于0) |
| NOX | 一氧化氮的浓度(百万分之几) |
| RM | 每个住宅的平均房间数 |
| AGE | 1940年之前建造的自有住房的比例 |
| DIS | 到五个波士顿就业中心的加权距离 |
| RAD | 径向公路通达性的指标 |
| TAX | 每一万美元的全值财产税率 |
| PTRATIO | 各镇的师生比率 |
| B | 计算方法为 $1000(B_k-0.63)^2$,其中Bk是按城镇划分的非裔美国人的比例 |
| LSTAT | 底层人口的百分比(%) |
| price | 自有住房数的中位数,单位(千美元) |
基于上述数据,请完成以下问题:
建立波士顿房价预测模型并对预测结果进行评价。
问题分析
首先这道题目的很明确,数据一共是 $506×14$ 的一个矩阵,有十三维的自变量,通过建立一个模型来拟合回归出最终的因变量 price,即户主拥有住房价值的中位数。这是一个回归问题,综合考虑有以下两个思路
通过各种回归算法(GradientBoostingRegressor,RandomForestRegressor,ExtraTreesRegressor,LinearRegressor等)结合全部或部分自变量来回归最终的price
建立前馈神经网络模型,根据通用逼近定理,我们可以拟合此回归模型。
我们对上述模型来进行实现并确定评估标准来对他们进行比较,选择最优的模型作为预测模型。
算法流程
传统的回归算法
自变量的选择
首先,考虑到数据集中13列自变量其中某一些可能和最终的房价并无强相关性,如果全部使用进行预测可能会对模型引入噪声,因此我们首先计算了房价price与各个自变量之间的相关系数 $r$ ,其中 $r$ 计算公式如下: $$ r = \frac{\sum(x_i-\bar{x})(y_i-\bar{y})}{\sqrt{\sum(x_i-\bar{x})^2\sum(y_i-\bar{y})^2}} $$ 其中 $x_i,y_i$ 为数据的每个分量,$\bar{x},\bar{y}$ 为数据的均值
该系数反映了两变量之间的相关性,$r$ 的绝对值介于 $[0,1]$ 区间内,$|r|$ 越接近1,表示两数据相关性越高,反之越低。计算后结果如下:
| CRIM | ZN | INDUS | CHAS | NOX | RM | LSTAT |
|---|---|---|---|---|---|---|
| -0.385832 | 0.360445 | -0.483725 | 0.175260 | -0.427321 | 0.695360 | -0.737663 |
| AGE | DIS | RAD | TAX | PTRATIO | B | |
| -0.376955 | 0.249929 | -0.381626 | -0.468536 | -0.507787 | 0.333461 |
观察结果可以发现,在给定的十三个变量中,LSTAT 与 price 的相关程度最高$(|r|>0.7)$,其次是 RM 与PTRATIO $(|r|>0.5)$,再者是 TAX,INDUS,NOX $(|r|>0.4)$,除上述之外的七个变量都与 price 无较强的相关性,因此我们考虑使用六个相关性较强变量和十三个变量分别来对房价进行预测,并对他们进行对比,来寻找最优的回归模型。
模型的构建
首先我们使用了sklearn中自带的 boston 数据集,并将整体数据集随机划分为了训练集和测试集两部分,所占比例分别为80%和20%。
然后,我们利用Linear,Ridge,Lasso,ElasticNet,DecisionTree,GradientBoosting,RandomForest,ExtraTrees八种模型通过训练集对其进行训练。
接下来,我们利用训练集拟合得到的模型,使用测试集对其进行测试,与 Ground Truth 进行对比,并通过 $R^2$ 来评价该预测结果,其中 $R^2$ 计算公式如下,其是衡量回归模型好坏的常见指标,其值一般处于[0,1]之间,$R^2$ 越接近1,说明模型的性能越好。 $$ R^2 = 1-\frac{\sum(\hat{y_i}-y_i)^2}{\sum(\bar{y}-y_i)^2} $$
最后,考虑到模型的训练及预测可能具有偶然性,因此我们对于每一个模型进行20次训练及预测,利用20次的结果对其进行综合评价。利用得到的结果绘制 箱线图 所得结果如下:
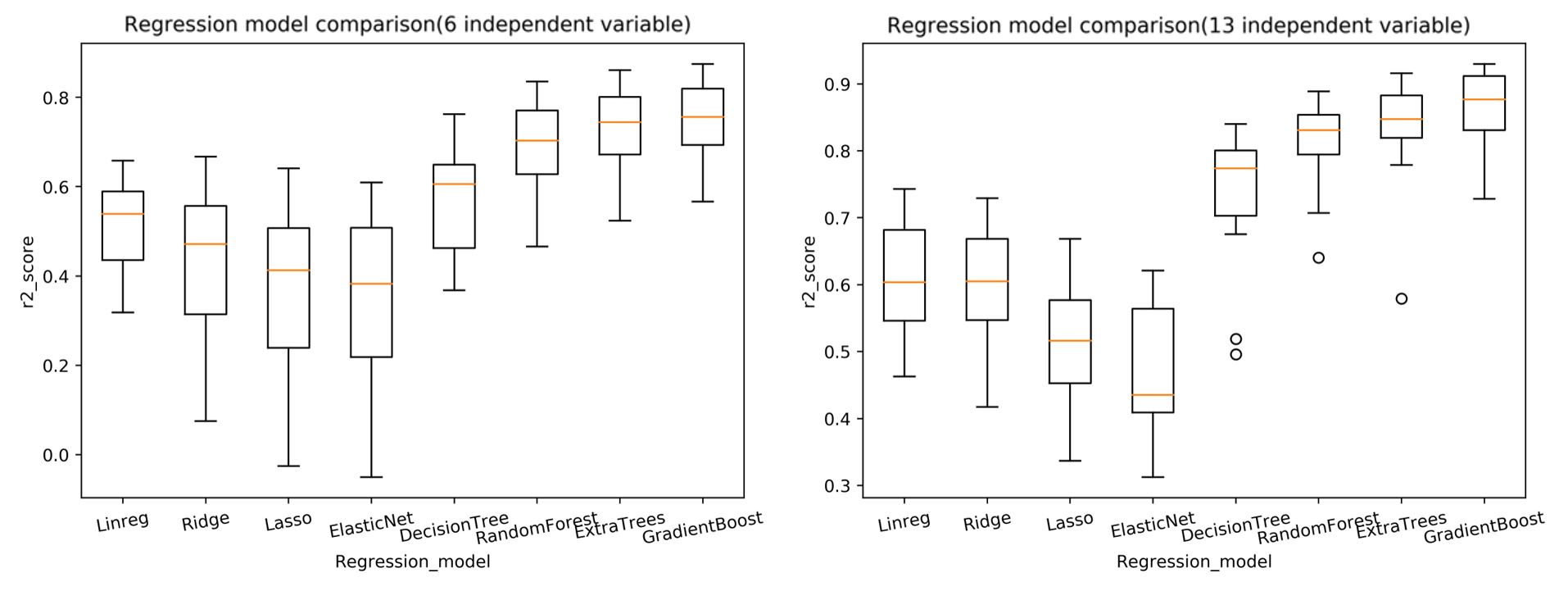
分析最终结果可以发现,无论是使用六个相关性较强变量还是十三个变量来进行预测,GradientBoost(梯度提升决策树)回归模型都是最好的,此外,我们可以发现,利用十三个变量要比利用六个主要变量来进行预测比有着更好的效果。
前馈神经网络
模型的构建
近年来,神经网络理论不断发展,前馈神经网络(多层感知机、全连接神经网络)越来越多的被利用到数据分析中,因此考虑使用前馈神经网络来解决此问题。
前馈神经网络(全连接神经网络)的网络结构一般由三部分构成,输入层,隐藏层,以及输出层,输入层与输出层一般只有一层,隐藏层可有多层。中间利用非线性函数作为激活函数可以使得网络具有拟合非线性函数的能力
根据通用近似定理:
通用近似定理
对于具有线性输出层和至少一个使用“挤压”性质的激活函数的隐藏层组成的前馈神经网络,只要其隐藏层神经元的数量足够,它可以以任意精度来近似任何从一个定义在实数空间中的有界闭集函数。
只要隐藏层网络维度够高,就可以拟合任意的函数。
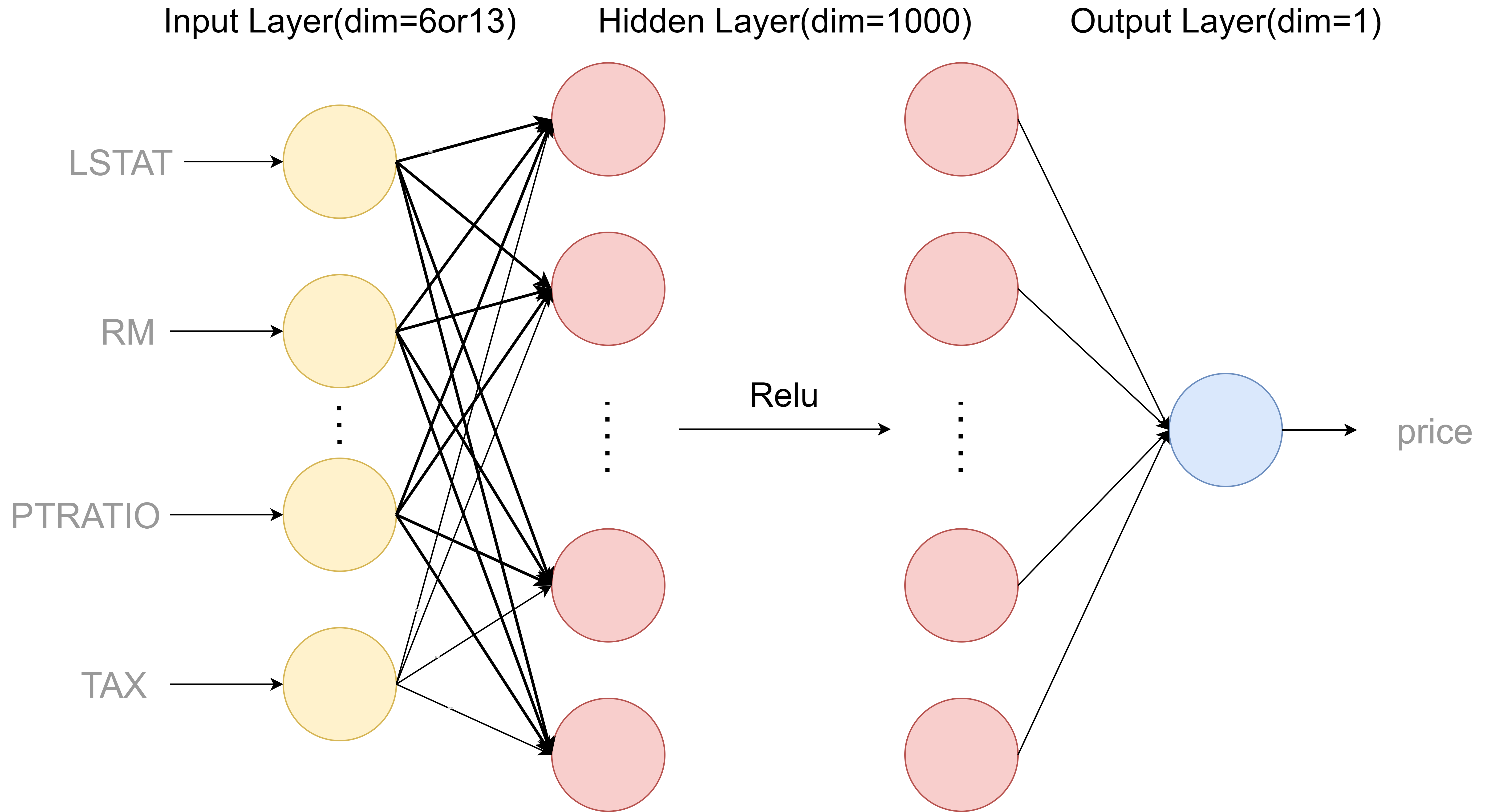
考虑到我们的模型有六维or十三维的数据输入,因此我们建立两层前馈神经网络,中间具有一层隐藏层,维度为1000维,激活函数使用Relu,Relu函数有以下优点:
Relu相比于传统的Sigmoid、Tanh,导数更加好求,反向传播就是不断的更新参数的过程,因为其导数不复杂形式简单,可以使得网络训练更快速。
此外,当数值过大或者过小,Sigmoid,Tanh的导数接近于0,Relu为非饱和激活函数则不存在这种现象,可以很好的解决梯度消失的问题
Relu函数及网络结构图如图所示:
$$ Relu:f(x) = max(0,x) $$
具体实现
利用流行的深度学习框架 Pytorch 来对模型进行实现。
- 首先,将数据集随机划分为训练集和测试集两部分,分别占80%和20%,并将其转化为Pytorch中的张量形式。
- 然后,利用MinMaxScaler对输入数据进行归一化,利用下列公式将其统一归一化为 $[0,1]$ 之间,以求模型能够更快的收敛。
$$ MinMaxScaler:x^{*} = \frac{x-min(x)}{max(x)-min(x)} $$
- 接下来,构建网络模型,利用 mseloss 作为损失函数,在训练过程中利用反向传播使其最终收敛为0。
$$ MseLoss = \frac{1}{2n}\sum||y(x)-a^L(x)||^2 $$
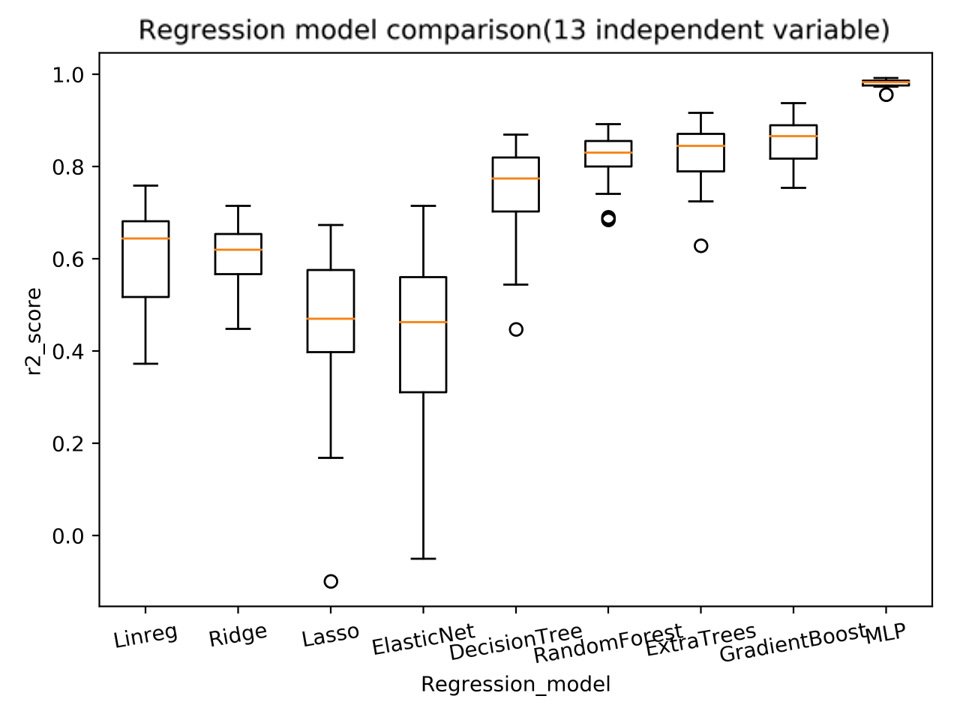
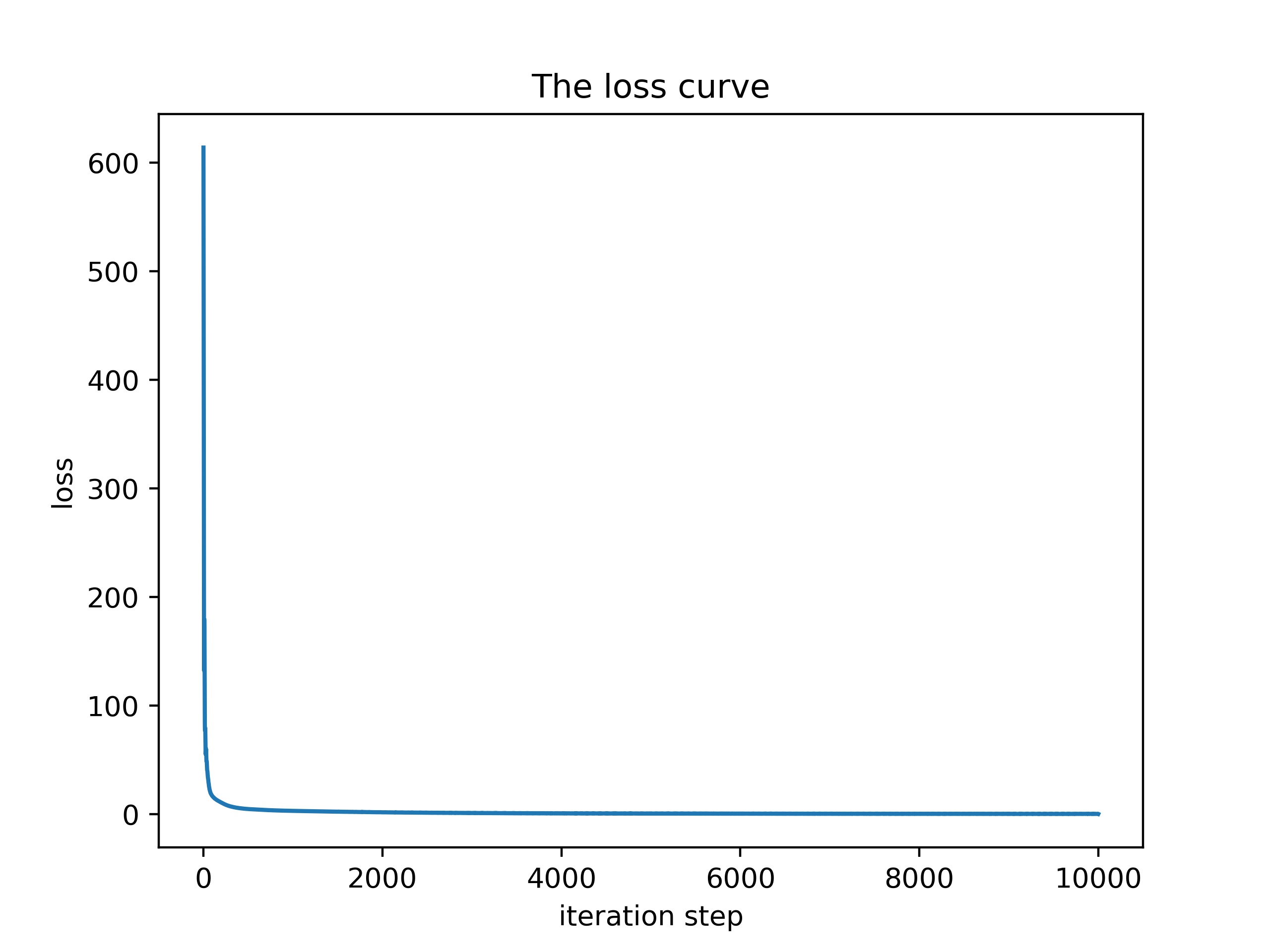
- 最后,我们设置网络的学习率为0.01,训练10000个epoch,发现其loss最终降低到0.3%左右,我们利用上文提到的 $R^2$ 对结果进行评估并与回归模型进行对比,通过观察图片可以发现,前馈神经网络相比于传统的回归模型有着更好的拟合效果, 20次预测得到的$R^2$平均值达到了0.95,此外中位数,最大值,最小值也要比回归模型更加优秀,因此我们采用前馈神经网络模型来对最后的房价进行预测。
最终预测
最终我们利用构建的前馈神经网络模型进行预测,利用测试集对其进行对比,绘制预测如下:
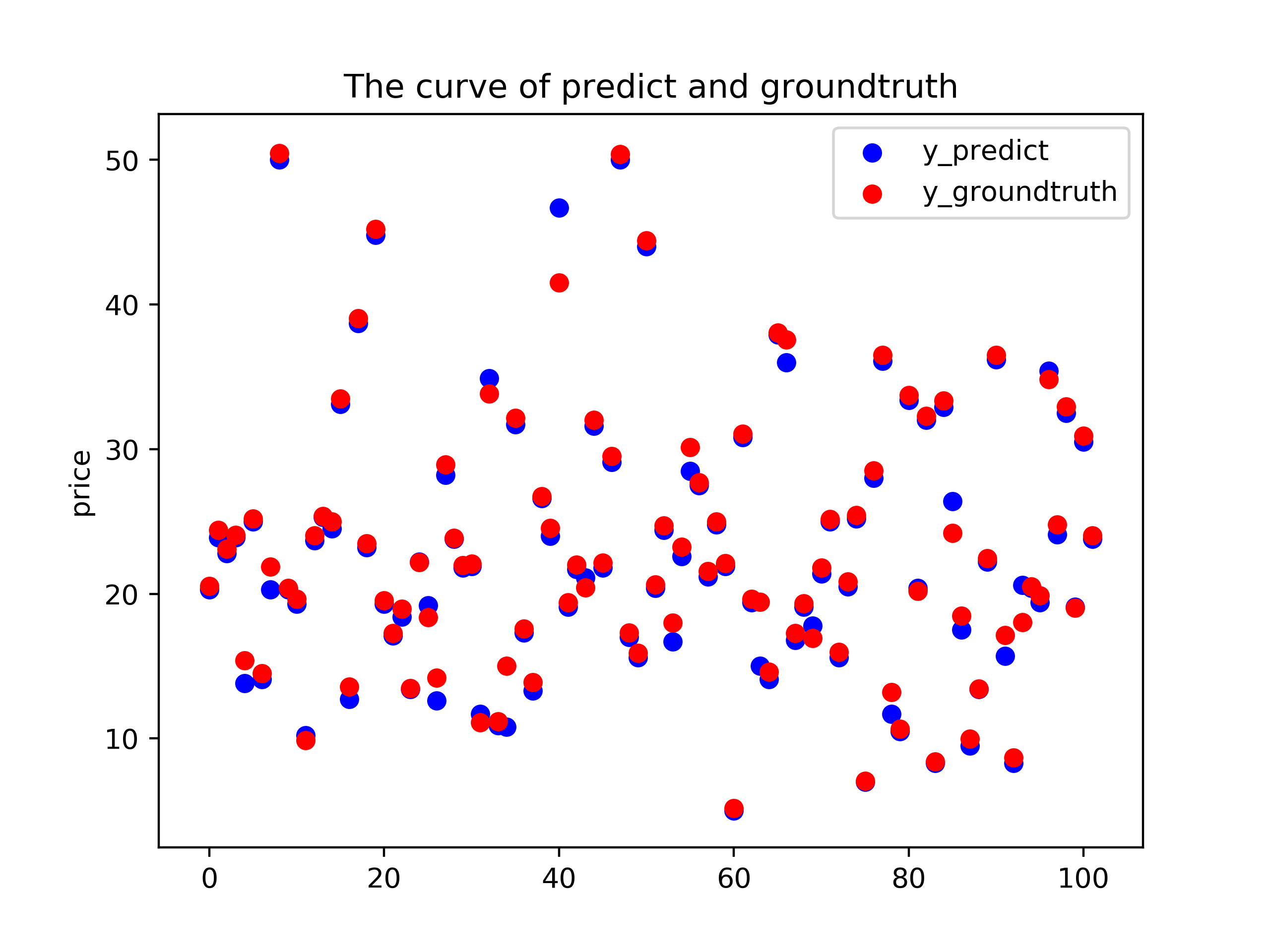
可以看到其中很多点都覆盖的很好,即预测准确。
通过理论对模型进行量化分析,计算预测的 $R^2$ $$ R^2 = 1-\frac{\sum(\hat{y_i}-y_i)^2}{\sum(\bar{y}-y_i)^2} = 1-0.01357 = 0.98643=98.643% $$ 可以发现 $R^2$ 十分接近1,说明回归模型性能良好,符合要求。
实现代码
代码放在我的Github了,其中写了较详细的README,链接为 BostonPredict